学术科研
Research


会议议程:
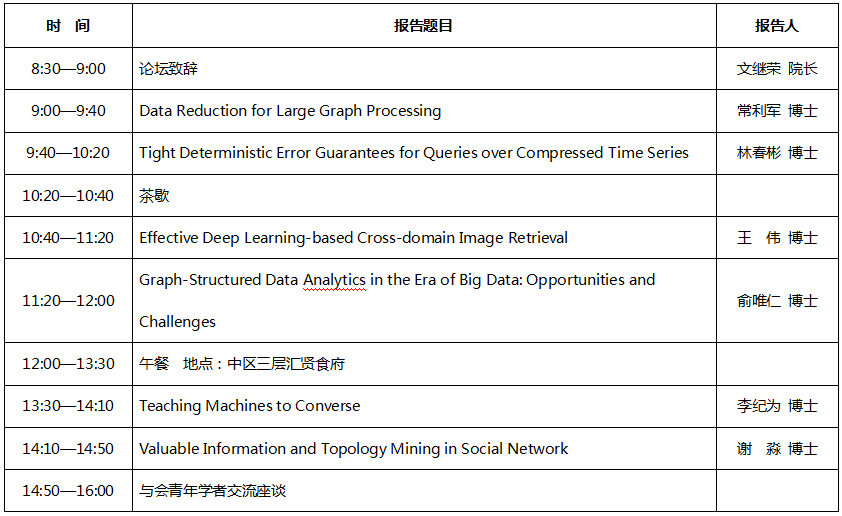
Title1: Data Reduction for Large Graph Processing
Speaker: Dr.Lijun Chang
 With the proliferation of graph applications and the recent advent of Big Data, research efforts have been devoted towards many fundamental problems in managing and analysing big graph data. In this talk, I will illustrate the power of using data reduction techniques for processing large real-world graphs, by investigating two graph processing problems. Firstly, I will briefly show that data reduction can significantly reduce the input graph instance for computing the densest subgraph (i.e., the subgraph with the maximum average degree). Secondly, I will illustrate in detail that data reduction techniques can be used to significantly improve the accuracy of heuristically computing a large independent set of a graph.
With the proliferation of graph applications and the recent advent of Big Data, research efforts have been devoted towards many fundamental problems in managing and analysing big graph data. In this talk, I will illustrate the power of using data reduction techniques for processing large real-world graphs, by investigating two graph processing problems. Firstly, I will briefly show that data reduction can significantly reduce the input graph instance for computing the densest subgraph (i.e., the subgraph with the maximum average degree). Secondly, I will illustrate in detail that data reduction techniques can be used to significantly improve the accuracy of heuristically computing a large independent set of a graph.
Short Bio: Lijun Chang is currently a Lecturer in the School of Information Technologies at the University of Sydney. He received his B.Eng. in computer science and technology from Renmin University of China in 2007, and Ph.D. in Systems Engineering and Engineering Management from Chinese University of Hong Kong in 2011. Prior to joining the University of Sydney, he was an ARC DECRA (Discovery Early Career Researcher Award) fellow at University of New South Wales. His research interests are in the fields of big graph (network) analytics, with a focus on devising practical algorithms and theoretical foundations for massive graph analysis. He has published over 40 papers in top-tier Database conferences and journals, including 8 SIGMOD papers, 10 PVLDB papers, and 7 VLDB Journal papers among many others.
Title2: Tight Deterministic Error Guarantees for Queries over Compressed Time Series
Speaker: Dr.Chunbin Lin
 We provide sound and tight deterministic error guarantees for approximate queries over compressed data. The query expressions are compositions of well-known linear algebra operators over vectors, along with arithmetic operators. Such queries can express most common statistics, including statistics (such as correlation and cross-correlation) that combine multiple time series. The queries are evaluated over classic time segment-based compressions of IoT time series. The error guarantees computations use common and straightforward precomputed error measures for each segment. Overall, the error guarantees are applicable (as an add-on) to most prior works on compression. In particular, the compression may use either fixed-length segmentation or (the far more effective in practice) variable-length segmentation. The estimation functions used to approximate the actual values may come from any function family.
We provide sound and tight deterministic error guarantees for approximate queries over compressed data. The query expressions are compositions of well-known linear algebra operators over vectors, along with arithmetic operators. Such queries can express most common statistics, including statistics (such as correlation and cross-correlation) that combine multiple time series. The queries are evaluated over classic time segment-based compressions of IoT time series. The error guarantees computations use common and straightforward precomputed error measures for each segment. Overall, the error guarantees are applicable (as an add-on) to most prior works on compression. In particular, the compression may use either fixed-length segmentation or (the far more effective in practice) variable-length segmentation. The estimation functions used to approximate the actual values may come from any function family.
This work identifies two broad estimation function families (namely, the already existing Vector Space family (VS) and the presently defined Linear Scalable Family (LSF)) that lead to theoretically and practically high-quality guarantees, even for queries that combine multiple time series. Well known function families (e.g., the polynomials) belong to LSF. The theoretical aspect of "high quality" is crisply captured by the Amplitude Independence (AI) property: An AI guarantee does not depend on the amplitude of the involved time series, even when we combine multiple time series. The experiments on four real-life datasets validated the importance of the Amplitude Independent (AI) error guarantees: When the novel AI guarantees were applicable, the guarantees could ensure that the approximate query results were very close (typically 1%) to the true results.
Short Bio: Chunbin Lin received his B.Sc and M.Sc from Renmin University of China in 2010 and 2013 respectively. He is currently a Ph.D. candidate in the Department of Computer Science and Engineering at the University of California, San Diego (UCSD). His research interest is in the general area of big data analytics including approximate query processing, data compression, and data integration. He published several papers in top conferences/journals, such as SIGMOD, PVLDB, ICDE, TODS, and VLDB Journal, and he is also a reviewer of several international journals like VLDB Journal.
Title3: Effective Deep Learning-based Cross-domain Image Retrieval
Speaker: Dr.Wei Wang
 With the proliferation of e-commerce websites and the ubiquitousness of smart phones, cross-domain data retrieval is emerging as an effective search paradigm that enables seamless information retrieval from various types of media. In this talk, I will introduce two applications of cross-domain information retrieval and the corresponding solutions. The first application enables users to query data with different modality as the query. For example, users snap a movie poster to search for relevant reviews and trailers. The second application supports image search with the query and database images from different domains. For instance, users search on the e-commerce website using query images captured by smartphones. For both tasks, the challenge lies in finding good representation for data from different domains. Deep learning based models will be introduced for the two tasks respectively.
With the proliferation of e-commerce websites and the ubiquitousness of smart phones, cross-domain data retrieval is emerging as an effective search paradigm that enables seamless information retrieval from various types of media. In this talk, I will introduce two applications of cross-domain information retrieval and the corresponding solutions. The first application enables users to query data with different modality as the query. For example, users snap a movie poster to search for relevant reviews and trailers. The second application supports image search with the query and database images from different domains. For instance, users search on the e-commerce website using query images captured by smartphones. For both tasks, the challenge lies in finding good representation for data from different domains. Deep learning based models will be introduced for the two tasks respectively.
Short Bio: Dr. Wei Wang is an Assistant Professor in the Department of Computer Science, National University of Singapore (NUS). He got his B.S. from Renmin University of China in 2011 and PhD from NUS in 2017. His research interests include deep learning systems and applications for multimedia data. He has publications in top conferences and journals including VLDB, ACM MM, VLDBJ, TOMM, SIGMOD Record.
Title4: Graph-Structured Data Analytics in the Era of Big Data: Opportunities and Challenges
Speaker: Dr.Weiren Yu
 Graphs are fundamental representations of many complex structured data with a broad spectrum of applications in e.g., web search, biological networks, social graphs, infrastructure networks. Over the last decade, tremendous research efforts have been devoted to many fundamental problems in managing and analysing graph-structured data. In this talk, I will present a series of our recent work in developing scalable techniques that can efficiently process graph-structured data and accept live updates to the large graph.
Graphs are fundamental representations of many complex structured data with a broad spectrum of applications in e.g., web search, biological networks, social graphs, infrastructure networks. Over the last decade, tremendous research efforts have been devoted to many fundamental problems in managing and analysing graph-structured data. In this talk, I will present a series of our recent work in developing scalable techniques that can efficiently process graph-structured data and accept live updates to the large graph.
Short Bio: 俞唯仁 (Weiren Yu),现任英国阿斯顿大学计算机科学系助理教授。研究领域包括:基于大规模拓扑网络结构的信息检索、动态流数据的实时分析,以及这些大数据处理技术在信息物理融合系统与物联网、动态社交网络、Web查询等方面的应用。2014至2016年任帝国理工学院Research Fellow,与Intel公司联合从事伦敦智能水系统网络的大数据分析与物联网研究。2010至2014年在澳大利亚新南威尔士大学攻读博士学位。近年来在数据库与信息检索领域国际会议(如VLDB、SIGIR、WWW、ICDE、ACL等)及期刊(如VLDB J., IEEE TKDE, IEEE TIFS)上发表了30余篇论文,其中5篇会议论文获Best Paper Award,1篇获One of ICDE Best Papers,1篇获Best Student Paper Award。目前主持两项英国国家自然科学基金EPSRC DTP项目、Aston Vice-Chancellor科研基金等。
Title5: Teaching Machines to Converse
Speaker: Dr.Jiwei Li
 Recent advances in neural network models present both new opportunities and challenges for developing conversational agents. Current chatbot systems still face a variety of issues: they tend to output dull and generic responses such as "I don't know what you are talking about"; they lack a consistent or a coherent persona; they are usually optimized through single-turn conversations and are incapable of handling the long-term success of a conversation; and they are not able to take the advantage of the interactions with humans.
Recent advances in neural network models present both new opportunities and challenges for developing conversational agents. Current chatbot systems still face a variety of issues: they tend to output dull and generic responses such as "I don't know what you are talking about"; they lack a consistent or a coherent persona; they are usually optimized through single-turn conversations and are incapable of handling the long-term success of a conversation; and they are not able to take the advantage of the interactions with humans.
In this talk, I will discuss how we can handle the issues mentioned above, and how to design a chatbot that is able to output more interesting, interactive and human-like responses. Specifically, I will talk about how to avoid the pitfall of outputting dull responses using mutual information; how to incorporate speaker embedding into the neural generation model to endow a bot with a coherent persona; how to handle the long-term success of a conversation using reinforcement learning and adversarial learning; and how to give a bot the ability to ask questions and make it smart about when to ask questions.
Short Bio: Jiwei Li just got his Ph.D in Computer Science from Stanford University, advised by Prof. Dan Jurafsky. His research interests lie in Natural Language Processing, with a focus on deep learning applications in dialogues, language generation and discourses. He was a recipient of Facebook fellowship of 2015, Baidu fellowship of 2016.
Title6: Valuable Information and Topology Mining in Social Network
Speaker: Dr. Miao Xie
 随着存储与计算能力的快速发展,涌现了很多基于社会网络的新应用,这些应用的在线系统中积累了大量用户行为的数据,如何从在线数据中高效、高质量地抽取出高价值信息并有效地提升在线系统的服务能力,是近年来学术研究的热点问题之一。本报告中,将首先介绍社会网络中的信息传播,拓扑结构挖掘和内容过滤与筛选,模型部署与系统安全性等一系列主要研究问题,然后逐个给出报告人在这些问题上的思考与研究进展,最后介绍了所提出方法在其他领域中的潜在价值,例如在软件工程中的应用案例。
随着存储与计算能力的快速发展,涌现了很多基于社会网络的新应用,这些应用的在线系统中积累了大量用户行为的数据,如何从在线数据中高效、高质量地抽取出高价值信息并有效地提升在线系统的服务能力,是近年来学术研究的热点问题之一。本报告中,将首先介绍社会网络中的信息传播,拓扑结构挖掘和内容过滤与筛选,模型部署与系统安全性等一系列主要研究问题,然后逐个给出报告人在这些问题上的思考与研究进展,最后介绍了所提出方法在其他领域中的潜在价值,例如在软件工程中的应用案例。
Short Bio: 谢淼是中国科学院软件研究所与新加坡南洋理工联合培养博士,获博士研究生国家奖学金,被评为北京市、中国科学院优秀博士毕业生。研究方向为社会网络分析,软件工程,数据库与分布式算法等,在AAAI, VLDB, ICSE, JPDC, ISSRE 等国际顶级会议及刊物上发表学术论文10 余篇,已申请国家专利9 项,撰写并出版本科教材1 部,被评为北京市精品教材。现任华为研究科学家&高级工程师,美国PMP 国际权威项目管理专业认证项目管理师。多项研究成果已产品化并集成进华为、联想、百度和中科方德等业内知名公司的产品与系统中。
Copyright © 2015 School of Information, Renmin University of China. All rights reserved.
版权所有中国人民大学信息学院