学院新闻
College News

近日,中国人民大学信息学院金琴教授团队AIM3多媒体计算实验室4篇长文被自然语言处理领域顶级会议ACL 2023录用。ACL(Annual Meeting of the Association for Computational Linguistics,计算语言学协会年会)是计算语言学和自然语言处理领域最重要的顶级国际会议之一,由国际计算语言学协会组织,是中国计算机学会(CCF)推荐的A类国际学术会议。
4篇论文第一作者分别是来自AIM3多媒体计算实验室的2019级博士生胡安文、2020级硕士生钱涛、2021级博士生杨丁一、2022级博士生岳子豪。
论文介绍
1. 论文题目:InfoMetIC: An Informative Metric for Reference-free Image Caption Evaluation
作者: 胡安文,陈师哲,张良,金琴
通讯作者:金琴
论文概述:
自动图像描述生成评测对于公平对比图像描述效果、促进图像描述领域发展进展至关重要。现有的指标只提供了一个单一的分数来衡量描述的质量,反馈的信息量较少,不具备可解释性,模型或研究人员很难根据这个得分来调整进一步优化模型的效果。相反,我们人类在进行图像描述评测时,往往能很容易地从细节上指出图像描述的问题,例如,哪些词描述地不准确,哪些图像中显著的对象没有被描述,然后再对描述质量进行评分。为了支持这样的富有信息量的反馈,我们提出了一个无需参考描述的图像描述评测指InfoMetIC。给定一张图片和一句描述,InfoMetIC能够在细粒度层面上指出错误的词语和未提及的视觉区域,并且能在粗粒度层面上提供一个文本准确率得分、一个视觉召回率分数和一个总体质量得分。在多个评测集上,InfoMetIC的粗粒度分数与人类判断的相关性明显优于现有指标。我们还构建了一个细粒度的评测数据集,并证明了InfoMetIC在细粒度评估中的有效性。

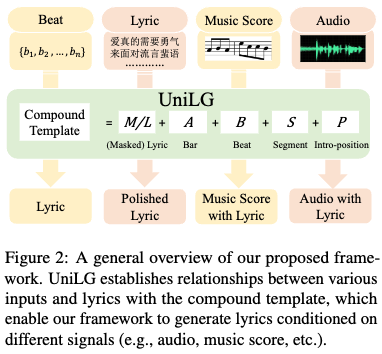
2. 论文题目:UniLG: A Unified Structure-aware Framework for Lyrics Generation
作者:钱涛,田中,史嘉彤,吴宇宁,郭帅,殷翔,金琴
通讯作者:金琴
论文概述:
条件的歌词生成作为自然语言生成的一项特殊任务,需要考虑生成歌词的主副歌结构以及歌词与音乐之间的关系。
由于各种形式的控制条件,歌词系统往往需要以不同信号为条件去生成歌词,例如音乐乐谱,音乐音频或半成品歌词等。但是,以前的大多数工作都忽略了歌词的主副歌结构和歌词背后隐藏的音乐属性。 此外,大多数歌词生成工作仅处理有限的歌词生成条件且严重依赖于成对的数据语料,它们不容易通过相同的框架扩展到其他的控制条件。
在本文中,我们提出了一个名为UniLG的统一结构化歌词生成框架。 具体来说,我们设计了包含文本和音乐信息以改善结构建模并统一不同歌词生成条件的复合模板,并且我们采用自动化的方式来构建训练UniLG所需的训练数据,使得框架所依赖的数据条件并不苛刻。
广泛的实验证明了我们框架的有效性。客观评估和主观评估都在产生主副歌结构的歌词方面有显着改善。
3. 论文题目:Attractive Storyteller: Stylized Visual Storytelling with Unpaired Text
作者:杨丁一,金琴
通讯作者:金琴
论文概述:
目前,针对风格化图像描述的研究已经在简单的风格上(例如积极和消极)取得了不错的效果。然而这些方法通常只是用单个句子中独特的单词或短语来体现相应的风格。而在实际中,文本风格会隐含在句法和篇章层面。相较于单句叙述,风格化故事更具吸引力,也更能体现某种写作风格。本文引入了一个新任务——风格化视觉故事叙述 (SVST),旨在为一组照片生成流畅的风格化故事。为解决这一任务,我们提出了名为StyleVSG的模型框架,通过在成对的 {图片序列-无风格故事}数据和非成对的 {风格化故事} 语料上进行联合训练,实现了风格准确性和视觉相关性之间的trade-off。其中对于非成对的风格化故事,我们基于CLIP模型构建伪数据对,以降低其他无监督方法容易带来的错误映射问题。为了保证故事的连贯性和一致性,我们设计了一个记忆模块,用于存储历史视觉信息和文本信息。实验表明,StyleVSG可以为图像序列生成具有各种风格(包括童话、浪漫和幽默)的连贯故事,并且在自动评测和人工评测指标上表现优于其他方法。

风格化视觉故事叙述(SVST)和其他任务的比较
4. 论文题目:Movie101: A New Movie Understanding Benchmark
作者:岳子豪,张琦,胡安文,张良,王子恒,金琴
通讯作者:金琴
论文概述:
为了帮助视障人士欣赏电影,自动电影解说系统需要在没有演员台词的情况下,生成准确、连贯且富含角色信息的剧情解说。现有的研究将这一挑战作为一个普通的视频描述任务,通过一些简化手段,例如去除角色名、使用基于n-grams的度量来评估解说质量,这使得自动系统很难满足真实应用场景的需求。为此,我们构建了一个大规模的中文电影基准,名为Movie101。该基准中的电影片段解说(Movie Clip Narrating, MCN)任务要求模型在没有演员说话的地方为完整的电影片段生成包含角色信息的解说段落,更贴近实际应用场景。同时,我们还提供了外部知识(如角色信息、电影类型等),以便模型能够更好地理解电影。此外,我们还提出了一种新的评测指标MNScore用于评估生成解说质量,它与人工评测更一致。我们的基准还支持时序解说定位(Temporal Narration Grounding, TNG)任务,以研究在给定文本解说的情况下,在整部电影中定位目标片段。对于这两个任务,我们提出的方法充分利用了外部知识,优于精心设计的基线。数据集和代码即将发布。


作者简介:
胡安文,中国人民大学信息学院2019级博士,大数据科学与工程专业,主要研究方向是图像描述生成,多模态预训练。

钱涛,中国人民大学信息学院2020级硕士,计算机应用技术专业,主要研究方向是语音、音乐和自然语言处理。

杨丁一,中国人民大学信息学院2021级博士,大数据科学与工程专业,主要研究方向是视觉与语言,跨模态文本生成。

岳子豪,中国人民大学信息学院2022级博士,大数据科学与工程专业,主要研究方向是视觉语言理解。

金琴,中国中国人民大学信息学院计算机系教授,多媒体计算实验室(AIM3)负责人。主要研究领域为多媒体智能计算、人机交互。

Copyright © 2015 School of Information, Renmin University of China. All rights reserved.
版权所有中国人民大学信息学院