学院新闻
College News

题目:Echo of Neighbors: Privacy Amplification for Personalized Private Federated Learning with Shuffle Model
作者:刘艺璇,赵素云,LiXiong,刘宇涵,陈红
团队:中国人民大学数据仓库与商务智能实验室、埃默里大学
论文接收情况:Accepted by AAAI2023
研究动机:
联邦学习是近年来兴起的一种多方合作的机器学习训练框架,它允许多个用户共同训练全局模型,而不需要交换本地数据集。尽管如此,联邦学习中依然蕴藏着大量隐私风险。攻击者可以通过观察全局模型或者中间参数推测参与训练的用户身份,甚至直接冲沟原始训练数据。因此,为全局模型和本地参数提供严格的隐私保护势在必行。此外,在现实场景中用户往往存在不同的隐私偏好。然而近期同时满足上述需求的研究成果,要么严重损伤模型过可用性,要么牺牲用部分用户的隐私。例如,个性化本地差分隐私算法通过不同的隐私参数设置,能够同时保护中心和本地的隐私,但是中心隐私会被拉低至最弱本地隐私水平。为同时满足中心和本地的强隐私保护需求,研究者提出了增强隐私性的混洗差分隐私方案。然而现有的混洗模型仅支持本地隐私需求一致的场景。因此,设计保护中心和本地隐私、满足个性化隐私需求同时维持模型可用性的联邦学习框架是联邦学习隐私保护的重要挑战。
研究方法:
为解决上述问题,我们提出了个性化隐私保护的联邦学习框架APES,通过引入混洗服务器,同时对隐私参数和隐私数据混洗,放大全局模型的隐私性。
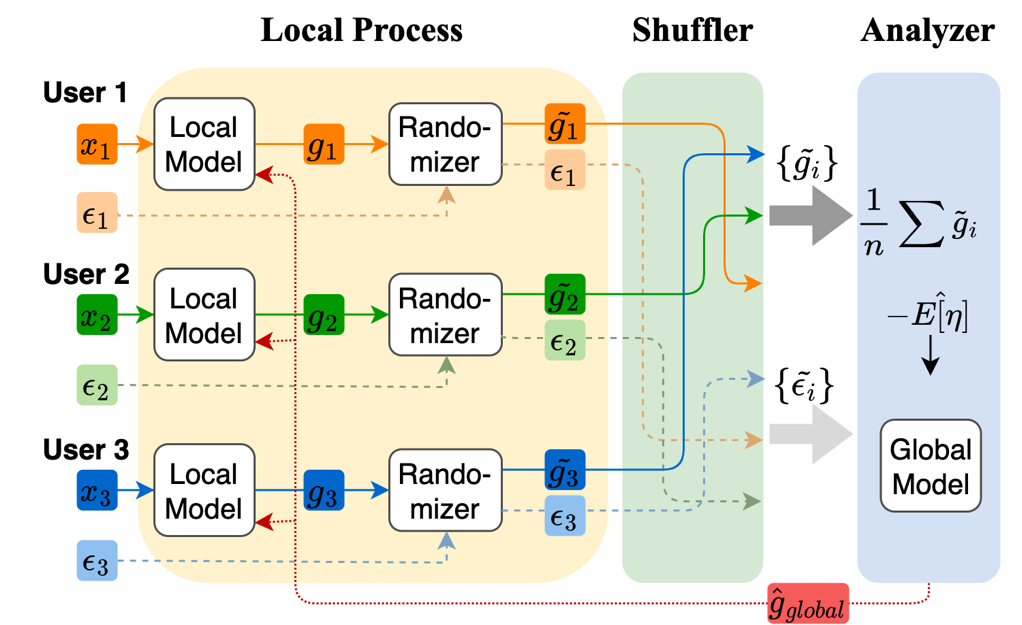
联邦混洗隐私保护框架
在APES框架中,我们首先提出截断拉普拉斯机制扰动本地梯度,在不影响模型可用性的同时控制相邻用户间的隐私损失。具体来说,截断拉普拉斯机制是拉普拉斯机制的变体,通过设计概率密度函数限制输入和输出的范围,确保用户在不同的噪声扰动下输出范围一致,满足差隐私且隐私损失有界。其次,我们通过混洗服务器同时混洗本地梯度和用户的隐私参数,为全局训练引入更多随机性。最后,中心服务器收集扰动的梯度和隐私参数,通过参数估计算法矫正截断拉普拉斯的偏差,获得平均的全局梯度。
为了提高该框架在高维场景下的隐私性,我们进一步提出基于后处理的稀疏化算法的框架S-APES,该算法对本地参数先扰动再选择最大的b维发送,其余维补0扰动发送。在此方法下,本地用户的隐私损失大幅降低,而不影响全局的混洗隐私放大效果。
联邦混洗隐私放大理论
现有的联邦混洗隐私放大理论仅针对用户隐私参数一致的情况。当参数不一致时,用户间的混淆作用难以衡量,隐私损失没有上界。因此,我们提出了基于APES框架的支持个性化隐私参数的放大理论EoN。
为分析全局隐私,我们通过量化用户间的混淆作用,精细地度量每个用户的个性化隐私水平下的扰动对于全局隐私的贡献程度,并将其转化为形式一致的混合分布以获取全局模型的隐私水平。为此,我们引入邻居散度的定义,通过定义两个用户在不同隐私参数下、相邻数据集间的扰动输出分布相似性,度量用户输出间的隐私损失。借助截断拉普拉斯机制,量化用户对邻居的保护能力。在此理论分析下,我们所获的的全局隐私水平得到极大程度的提高,隐私得以放大。
实验结果
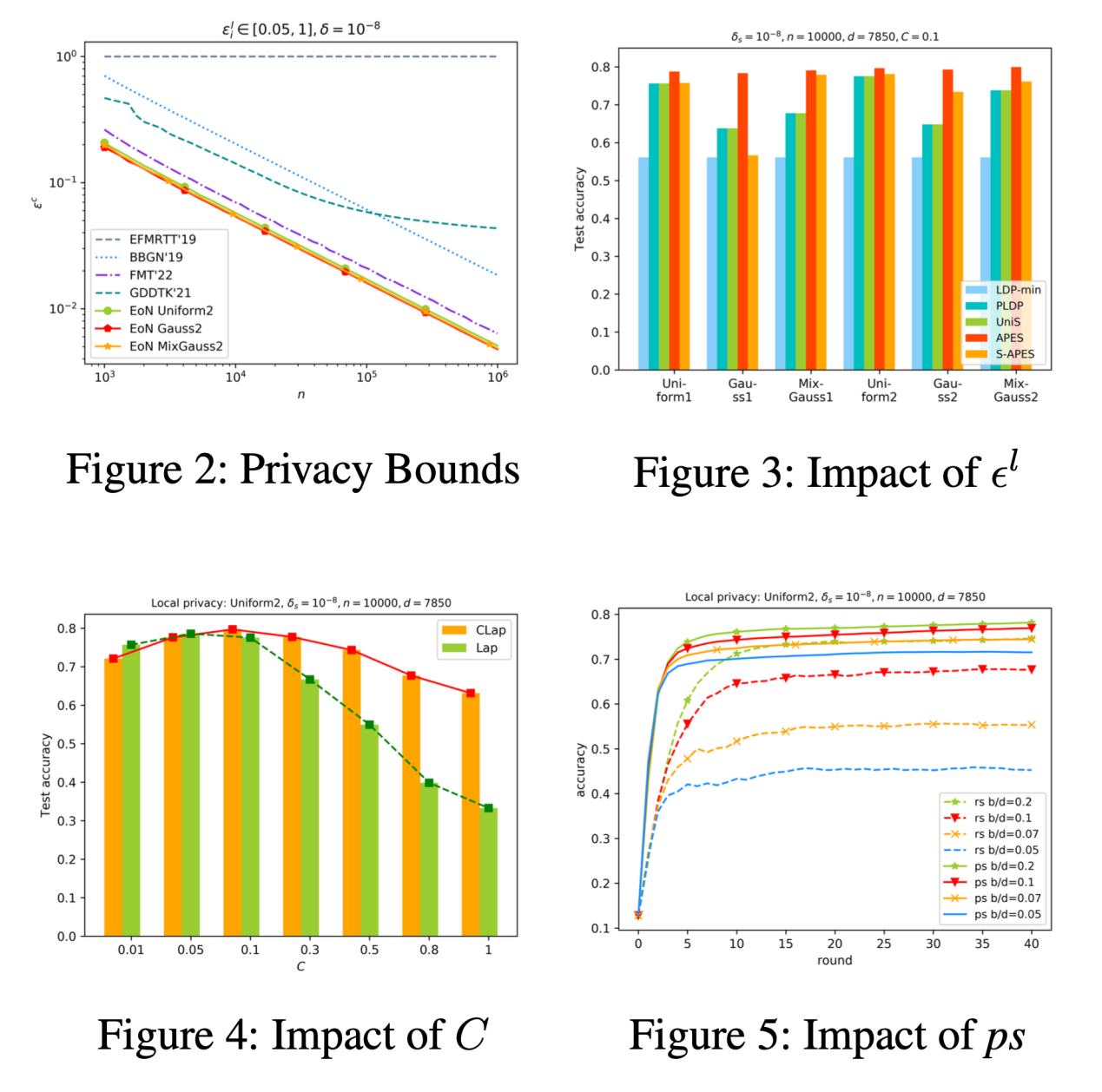
最后,我们在实验上验证了该框架的可行性,并展示了本文所提出的框架的隐私放大效果、截断拉普拉斯机制的特性、后处理的稀疏化策略的有效性。其中表3和图3展示了APES和S-APES在满足个性化本地隐私需求的前提下的高中心隐私水平和高准确性,且在多种本地隐私参数设置下都能达到良好的效果。图2中,在相同的本地隐私预算下,我们的方案达到的中心隐私损失最低,保护能力最强。且保护能力随着用户量n的增加而增强。图4验证了截断拉普拉斯机制在不同截断边界C下的可用性均可匹敌经典的拉普拉斯机制,且准确性随着C的增大而增加。最后我们在图5中展示了后处理的稀疏化策略的可用性,随着稀疏化程度增加,其准确性逐渐高于随机稀疏化这一基本方案。
综上所述,我们提出了基于混洗模型的个性化隐私保护的联邦学习框架和理论,能够在满足个性化本地隐私需求同时放大全局模型的隐私保护水平。实验证明,我们的方案在此强隐私保护的情况下依然能达到与基础方案持平甚至更高的模型准确性。

作者简介:
刘艺璇,中国人民大学信息学院2019级博士生,大数据科学与工程专业,主要研究方向为联邦学习中的隐私保护技术。参与“机器学习中的隐私保护”国家自然科学基金项目,曾在软件学报、AAAI等重要国内外期刊和会议发表一作论文2篇。

陈红,教授、博士生导师,中国人民大学信息学院党委书记兼副院长,中国计算机学会数据库专业委员会常务委员、物联网络专业委员会委员。先后主持国家重点研发计划、国家重大专项项目、国家973项目、国家863计划项目、国家自然科学基金重点项目等20余项,项目经费累计超过7000万元;在国内外学术期刊和学术会议上发表论文200余篇,出版数据库方面的著译作8部。获得国家发明专利多项。获教育部科技进步一等奖和二等奖、北京市科学技术进步二等奖(两次)、中国计算机学会科技进步一等奖、国家精品课程奖、国家精品资源公共课、北京市精品课程奖、北京市优秀教学成果一等奖、中国人民大学十大教学标兵等奖励,2005年入选教育部新世纪优秀人才支持计划。2018年当选中国计算机学会杰出会员。

Copyright © 2015 School of Information, Renmin University of China. All rights reserved.
版权所有中国人民大学信息学院