学院新闻
College News

近日,中国人民大学信息学院DBIIR实验室范举教授团队3篇长文1篇短文和张峰副教授团队1篇长文被SIGMOD 2023录用。SIGMOD(ACM SIGMOD International Conference on Management of Data,数据管理国际会议)是数据库领域具有最高学术地位的国际性学术会议,是中国计算机学会(CCF)推荐的A类国际学术会议,也是中国人民大学A+类学术会议。
范举教授团队的研究重点是数据准备以及更广泛的数据治理技术与系统,3篇长文第一作者分别是2020级硕士生涂荐泓、2022级硕士生辜子惠、2022级博士生陈思蓓,短文第一作者为2021级硕士生杨晨宇和2022级硕士生范瑞雪。张峰教授团队的研究重点是压缩数据直接计算数据库系统,长文第一作者是2020级博士生陈政。
标题:Unicorn: A Unified Multi-tasking Model for Supporting Matching Tasks in Data Integration
作者:涂荐泓(中国人民大学),范举(中国人民大学),汤南(卡塔尔计算研究所),王芃(中国人民大学),李国良(清华大学),杜小勇(中国人民大学),贾晓丰(北京市大数据中心),高嵩(北京市大数据中心)
通讯作者:范举
论文概述:
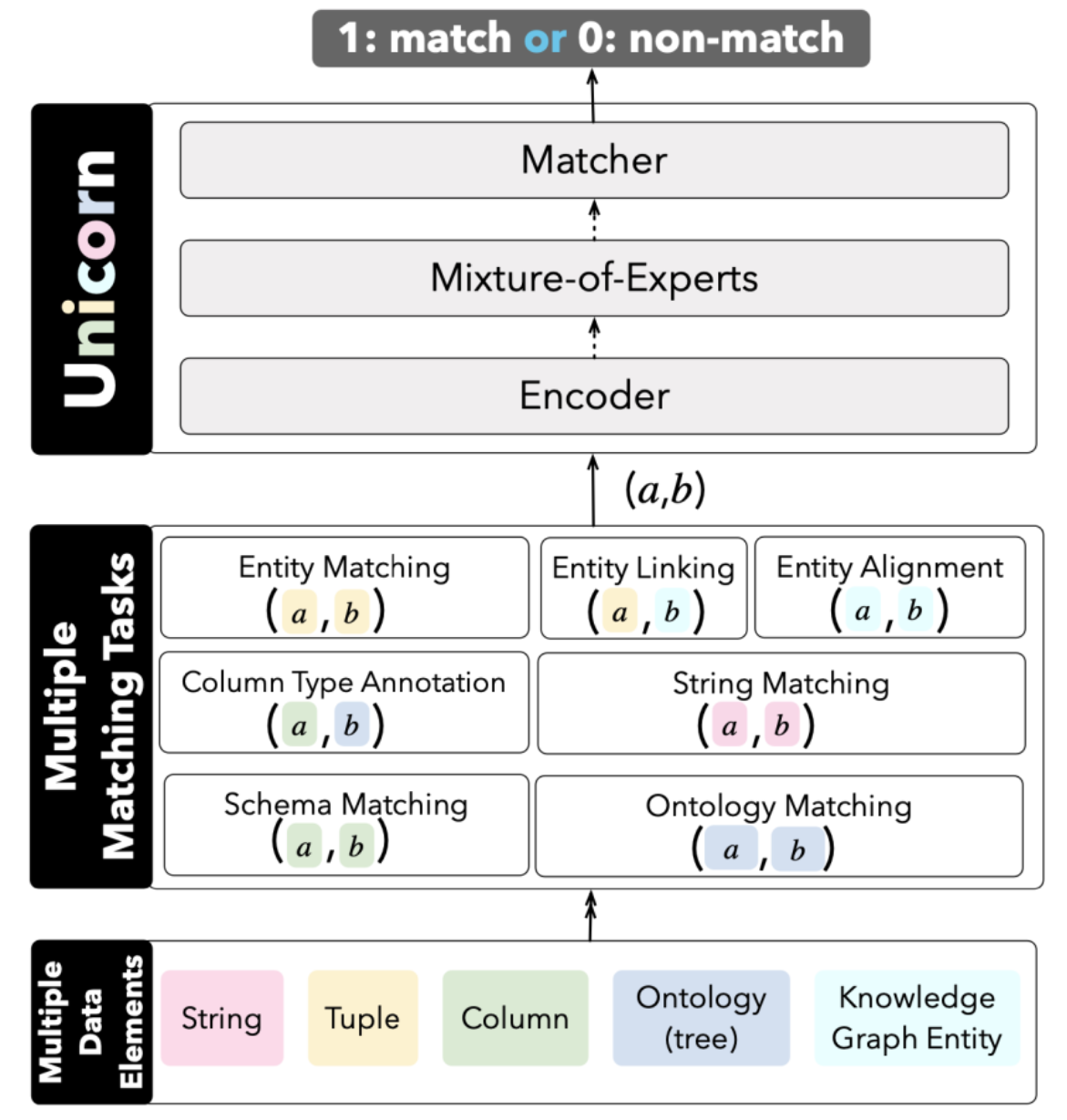
数据匹配是决定两个数据元素(如字符串、元组、列或知识图谱实体)是否“相同”的过程,是数据治理领域的重要研究问题。现有研究方案主要针对单个匹配任务或单个数据集设计特定的模型,本文提出同时支持多种匹配任务的统一模型Unicorn。优势主要在于将不同数据匹配任务统一到一个端到端的模型,并且多任务学习机制使得不同任务间可以共享知识,实现互相增益。Unicorn使用了一个通用编码器,它将任何一对数据元素(a, b)转换为高维向量表示,并使用一个二维分类器来决定a是否与b匹配。为了对齐不同任务的匹配语义,Unicorn采用了混合专家模型,将学习到的表示增强为更好的表示。文章针对7个常见的数据匹配任务的20个数据集进行了广泛的实验,发现与特定于任务和数据集的现有最佳模型相比,Unicorn在大多数任务上和平均水平上都能取得更好的性能。此外,Unicorn还可以对无标签的新任务很好地完成零样本预测。
标题:Few-shot Text-to-SQL Translation using Structure and Content Prompt Learning
作者:辜子惠(中国人民大学),范举(中国人民大学),汤南(卡塔尔计算研究所),曹磊(麻省理工大学CSAIL),贾博闻(中国人民大学),Sam Madden(麻省理工大学CSAIL), 杜小勇(中国人民大学)
通讯作者:范举
论文概述:
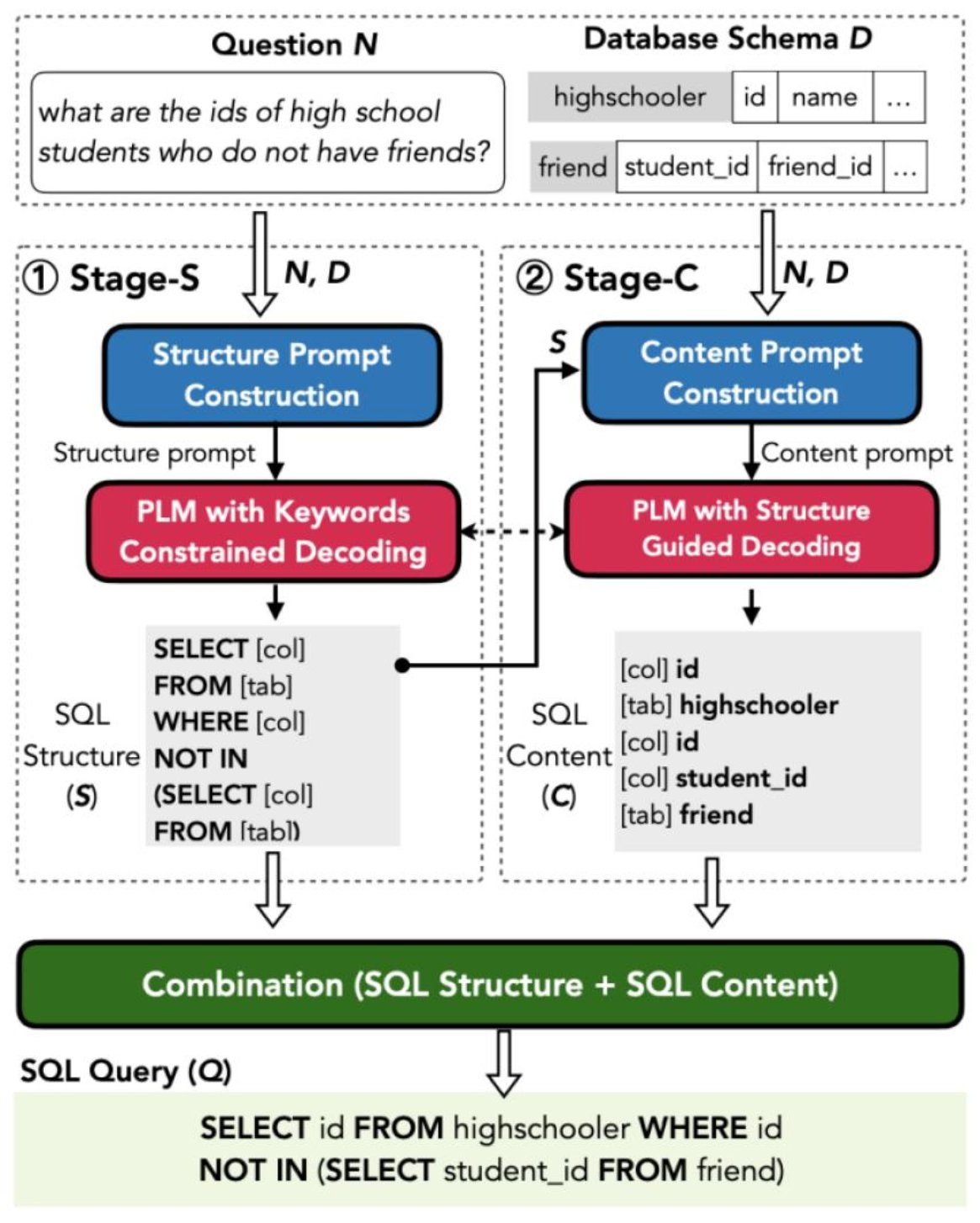
Text-to-SQL任务目标在于将自然语言问题转换为可执行的SQL查询,可以为不具备SQL知识的终端用户提供数据查询的自然语言接口。为了支持低数据量场景下的Text-to-SQL模型训练,本文提出了一个基于提示的两阶段学习框架SC-Prompt。给定一个自然语言问题和一个数据库,SC-Prompt首先学习如何生成SQL结构(包括关键词,运算符等),然后SQL结构会作为提示来指导模型生成其中的内容(包括表名,列名等)。由于两个子任务具有不同的学习目标,本文设计了一种混合提示机制来给预训练语言模型提供不同粒度的引导:使用任务描述作为文本提示来引入任务知识,引入可学习向量来建模细粒度的上下文语义关系,以帮助模型在预测的时候更好地建模文本数据和结构化数据之间的关系并做出正确的推理。此外,本文基于不同阶段的特点引入了细粒度的限制解码方法以生成合法的SQL查询。在多种类型的评测数据集上,SC-Prompt可以在多种低数据量设定下优于传统的端到端微调框架。
标题:HAIPipe: Combining Human-generated and Machine-generated Pipelines for Data Preparation
作者:陈思蓓(中国人民大学),汤南(卡塔尔计算研究所),范举(中国人民大学),严雪蜜(中国人民大学),柴成亮(清华大学),李国良(清华大学),杜小勇(中国人民大学)
通信作者:范举
论文概述:
数据准备对于机器学习(ML)的优化至关重要。然而,对于ML从业者来说,拥有一个良好的数据准备工作流是非常重要的。现有常见做法有两种:人工生成的工作流(HI-pipeline)通常广泛使用任意的操作或库,但它们是高度基于经验和启发式的。相比之下,机器生成的工作流(AI-pipeline),也称为AutoML,通常采用一组预定义的复杂操作,并基于搜索的方法进行优化。在本文中,我们研究了一个新问题,即给定同一机器学习任务的HI-pipeline和AI-pipeline,我们能否将它们结合起来,得到一个比所提供的HI-pipeline或AI-pipeline更好的新的工作流?我们提出了HAIPipe框架,它采用枚举-采样策略来仔细选择性能最好的组合工作流。我们还介绍了一种基于强化学习(RL)的方法来搜索优化的AI-pipeline。我们使用1400多个真实世界的HI-pipeline(Kaggle的Jupyter Notebook)进行的大量实验验证了HAIPipe可以显著优于单独使用HI-pipeline或AI-pipeline的方法。

标题:Pay “Attention” to Chart Images for What You Read on Text (短文)
作者:杨晨宇(中国人民大学),范瑞雪(中国人民大学),汤南(卡塔尔计算研究所),张美惠(北京理工大学),赵小曼(中国人民大学),范举(中国人民大学),杜小勇(中国人民大学)
通讯作者:范举
论文概述:
可视化图表对于分析和理解大量的数据非常重要。然而,随着可视化技术不断发展,用户越来越难在阅读时关注到图表中与文章文本对应的内容。由于文本中的数据可能是聚合、取整的结果或出现错误,它们有时候并不能直接在图表中找到。在本文中,我们研究了一个新的问题:给定一张图表和相关的自然语言文本,我们希望根据文本,将图表中相应的可视化部分进行高亮。为了解决该问题,我们提出了一个新颖的系统HiChart。HiChart包含了逆向工程可视化、可视化校准及图表高亮三个模块,前两个模块用于从图表中抽取包含准确数据的可视化规范,该规范内容能用于生成原始图表,第三个模块可以根据文本内容生成高亮代码加入可视化规范中。我们构建了一个网站并演示了HiChart在不同图表高亮场景下的效果,可以点击https: //youtu.be/3I5FEND3brE查看具体视频。

标题:CompressGraph: Efficient Parallel Graph Analytics with Rule-Based Compression
作者:陈政(中国人民大学),张峰(中国人民大学),官佳薇(中国人民大学),翟季冬(清华大学),慎熙鹏(北卡罗来纳州立大学),张焕晨(清华大学),舒文桐(中国人民大学),杜小勇(中国人民大学)
通信作者:张峰
论文概述:
大图数据对图分析应用带来了时间和空间上的双重挑战。我们提出了CompressGraph, 一个基于规则压缩的图分析框架。CompressGraph通过利用图中存在的数据冗余在通用的图应用上实现了时间和空间上的双重节省。CompressGraph相比于现有的工作有三点优势。第一,CompressGraph采用的基于规则的抽象可以支持在图遍历过程中的中间结果的复用,实现了性能提升。第二,CompressGraph有很强的表达能力去支持大范围的通用图应用。第三,得益于上下文无关的规则拥有极少的数据依赖,CompressGraph可以在高并行环境下实现很好的可扩展性。实验展示CompressGraph在CPU和GPU上都实现了显著的性能和空间提升。在六个典型的图应用上,与最先进的方法比较,CompressGraph可以在CPU上实现1.97倍的加速比,在GPU上可以实现3.95倍的加速比。除此之外,CompressGraph还可以分别在CPU和GPU平台上节省71.27%和70.36%的存储空间。

作者简介:
涂荐泓,中国人民大学信息学院2020级学术硕士,计算机应用技术专业,主要研究方向是数据库与数据融合,目前已发表4篇CCF-A类论文(VLDB和SIGMOD)。

辜子惠,中国人民大学信息学院2022级专业硕士,主要研究方向是自然语言处理。

陈思蓓,中国人民大学信息学院2022级博士,计算机应用技术专业,主要研究方向是数据准备工作流的生成与优化、数据验证。

杨晨宇,中国人民大学信息学院2021级专业硕士,主要研究方向是数据清洗和数据管理。

范瑞雪,中国人民大学信息学院2022级学术硕士,计算机应用技术专业。

陈政,中国人民大学信息学院2020级博士生,计算机应用技术专业,主要研究方向是大数据管理与分析。

范举,中国人民大学数据工程与知识工程教育部重点实验室教授、博士生导师、中国计算机学会数据库专家委员会委员、大数据专家委员会委员。近年来聚焦人在回路的数据融合、众包数据管理、大数据分析等研究方向,相关成果在计算机领域A类期刊和会议上发表论文40余篇。作为负责人主持了国家自然科学基金优青项目、面上项目、重点项目课题,以及多项腾讯犀牛鸟基金项目。

张峰,中国人民大学杰出学者,副教授,博士生导师,中国计算机学会数据库专委委员、高专委委员。研究方向为数据库系统与理论,近五年作为第一或通讯作者发表CCF A类论文30篇。曾获北京市教学成果一等奖、CCF-腾讯犀牛鸟基金卓越奖等奖励,2022年入选北京市科技新星人才计划。

Copyright © 2015 School of Information, Renmin University of China. All rights reserved.
版权所有中国人民大学信息学院