学院新闻
College News

中国人民大学信息学院张静教授团队有6项研究成果被ACL(Association for Computational Linguistics)所接受,其中5项被接收为主会论文,1项被接收为Findings论文。ACL是全球自然语言处理领域最权威的学术会议之一,涵盖大模型、语言理解、生成、翻译等前沿研究方向。每年吸引顶尖学者和研究机构参与,其论文代表了 NLP 领域的最新进展与最高水平。
论文概述1
标题: SAM Decoding: Speculative Decoding via Suffix Automaton
作者:胡雨轩(中国人民大学),王珂(中国人民大学),张晓康(中国人民大学),张帆进(清华大学),李翠平(中国人民大学),陈红(中国人民大学),张静(中国人民大学)
会议:ACL Main Conference
论文简述:
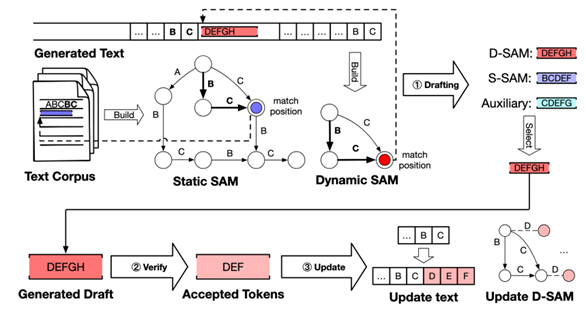
投机解码(Speculative Decoding,SD)已被证明是一种高效的无损大语言模型(LLM)推理加速技术。其中,基于检索的投机解码方法作为一类无模型方案,在实际应用中取得了不错的加速效果。然而,这些方法通常依赖于单一的检索源和效率较低的匹配策略,导致其在适用范围上受到限制,仅在特定任务中表现良好。为了解决这些问题,本文提出了一种新颖的基于后缀自动机(Suffix Automaton, SAM)的检索式投机解码方法——SAM-Decoding。该方法通过SAM对生成文本序列及静态语料库构建高效索引,实现快速且准确的草稿生成。与现有方法采用的 n-gram 匹配机制不同,SAM-Decoding 能够找到精确的最长后缀匹配,并在每个生成步骤中实现平均 O(1) 的时间复杂度进行检索和更新,显著提升了效率。此外,SAM-Decoding 还具备良好的兼容性,能够与现有的基于草稿模型的投机解码方法相结合,并根据当前匹配长度自适应地选择最优的草稿生成策略,从而扩展至更广泛的应用场景。本研究的代码已开源,欢迎访问https://github.com/RUCKBReasoning/SAM-Decoding获取。
论文概述2
标题: P2 Law: Scaling Law for Post-Training After Model Pruning
作者:陈晓栋(中国人民大学),胡雨轩(中国人民大学),张晓康(中国人民大学),王艳玲(中关村实验室),李翠平(中国人民大学),陈红(中国人民大学),张静(中国人民大学)
会议:ACL Main Conference
论文简述:
剪枝已成为一种广泛采用的技术,用于降低大语言模型(LLM)的硬件需求。为恢复剪枝后的模型性能,通常采用后训练来缓解由此产生的性能下降。虽然后训练受益于更大的数据集,但当数据集规模已经足够庞大时,增加训练数据带来的性能提升十分有限。为平衡后训练成本与模型性能,有必要探索最优的后训练数据量。通过对Llama-3和Qwen2.5系列模型进行大量实验(这些模型采用多种常见剪枝方法处理),我们揭示了模型剪枝后后训练的缩放规律,称为P2定律。该定律确定了四个预测剪枝模型后训练损失的关键因素:剪枝前的模型参数量、后训练Token数量、剪枝率以及剪枝前模型的损失。此外,P2定律可推广至更大规模数据集、更大模型尺寸和更高剪枝率场景,为剪枝后大语言模型的后训练提供了重要指导。
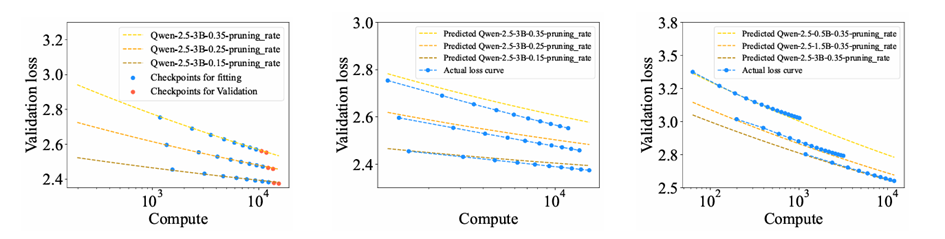
P2定律推广至更大规模数据集、更大模型尺寸和更高剪枝率场景
论文概述3
标题: Dynamic Scaling of Unit Tests for Code Reward Modeling
作者:马泽尧*(中国人民大学),张晓康*(中国人民大学),张静(中国人民大学),于济凡(清华大学),罗思佳(中国人民大学),唐杰(清华大学)
会议:ACL Main Conference
论文简述:
当前大语言模型(LLMs)在处理代码生成等复杂推理任务时,常常无法在首次生成中就给出正确答案,且倾向于在错误答案上表现出高度自信,这种“自信地犯错”现象严重影响了模型的可靠性。已有方法通过生成多个候选解并使用模型自动生成的单元测试进行验证,利用测试结果作为奖励信号来筛选正确解。然而,由于这些单元测试本身也可能出错,导致奖励信号质量受限。我们发现,增加单元测试的数量可以有效提升奖励信号的准确性,尤其在处理更具挑战性的问题时效果更为显著。为此,我们提出了轻量高效的单元测试生成模型 CodeRM-8B,并引入了一种根据问题难度动态调整测试数量的机制,以提升整体效率和性能。实验结果显示,该方法在多个主流模型上均取得了显著提升,例如 Llama3-8B 和 GPT-4o-mini 在 HumanEval Plus 上分别提升了 18.43 和 3.42。主页:https://code-reward-model.github.io/

论文概述4
标题: CoT-based Synthesizer: Enhancing LLM Performance through Answer Synthesis
作者:张博涵*(中国人民大学),张晓康*(中国人民大学),张静(中国人民大学),于济凡(清华大学),罗思佳(中国人民大学),唐杰(清华大学)
会议:ACL Main Conference
论文简述:
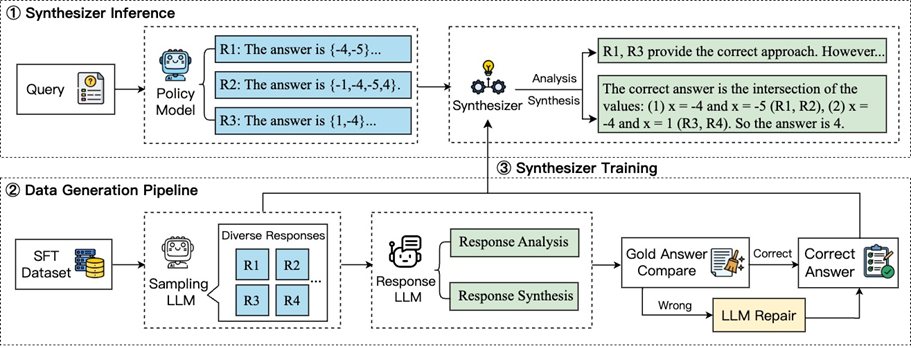
当前的Self-consistency和Best-of-N等推理扩展方法已被证明能有效提升大语言模型在复杂推理任务中的准确性。然而,这些方法高度依赖候选回答的质量,当所有候选答案均错误时便无法生成正确结果。因此,我们提出了一种新型的推理扩展策略——基于思维链的答案合成器(CoT-based Synthesizer),该策略通过分析多个候选回答中的互补信息,即使所有候选回答均存在缺陷,也能利用思维链推理合成更优答案。为实现轻量低成本的部署,我们还引入了训练数据的自动合成流程,可创建多样化的训练数据。经过该数据训练的小型语言模型能够提升包括API大模型在内的更大模型的推理准确率。在七个主流模型、四个基准数据集上的实验表明,我们的方法显著提升了模型性能:例如在MATH数据集上,Llama3-8B模型性能提升11.8%,GPT-4o提升10.3%。主页:https://github.com/RUCKBReasoning/CoT-based-Synthesizer
论文概述5
标题:Uncovering the Impact of Chain-of-Thought Reasoning for Direct Preference Optimization: Lessons from Text-to-SQL
作者:刘涵冰*(中国人民大学),李好洋*(中国人民大学),张晓康(中国人民大学),陈若彤(中国人民大学),徐海勇(中国移动),田天(中国移动),祁琦(中国人民大学),张静(中国人民大学)
会议:ACL Main Conference
论文简述:
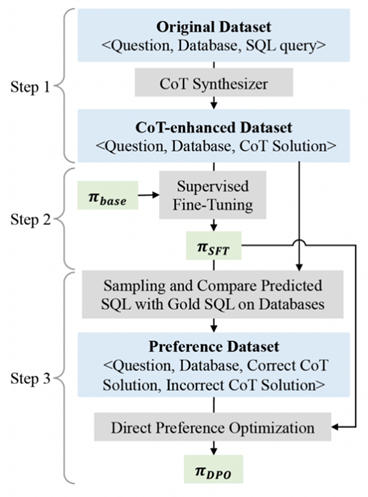
直接偏好优化(DPO)在数学应用题和代码生成等复杂推理任务中已被证实有效,但当应用于Text-to-SQL数据集时,其性能往往无法提升甚至会出现下降。我们的研究发现其根本原因在于:与数学和代码任务不同(这类任务天然适合将思维链推理与DPO结合),Text-to-SQL数据集通常仅包含最终答案(标准SQL查询),而缺乏详细的思维链解答步骤。通过为Text-to-SQL数据集注入合成的思维链解答步骤,我们首次实现了使用DPO在该任务上带来持续且显著的性能提升。我们还发现,思维链推理对于释放DPO潜力具有关键作用:它能有效缓解奖励破解(Reward hacking)现象、增强奖励模型判别能力并提升生成模型扩展性。这些发现为构建更稳健的Text-to-SQL模型提供了重要启发。为促进后续研究,我们公开相关代码及经思维链增强的数据集:https://github.com/RUCKBReasoning/DPO_Text2SQL
论文概述6
标题: TableLLM: Enabling Tabular Data Manipulation by LLMs in Real Office Usage Scenarios
作者:张晓康*(中国人民大学),罗思佳*(中国人民大学),张博涵(中国人民大学),马泽尧(中国人民大学),张静(中国人民大学),李扬(中国人民大学),李冠霖(中国人民大学),姚子俊(清华大学),Kangli Xu(清华大学),jinchang Zhou(清华大学),张李牛牛(清华大学),于济凡(清华大学),Shu Zhao (安徽大学),李涓子(清华大学),唐杰(清华大学)
会议:ACL Findings
论文简述:
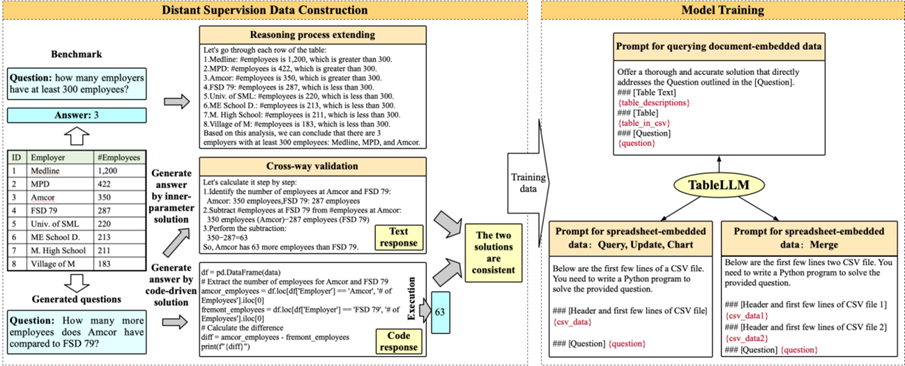
我们提出了 TableLLM,这是一个拥有80亿参数的大语言模型(LLM),专门为高效处理嵌入在文档或电子表格中的表格数据操作任务而设计,适用于真实办公场景。我们提出了一种用于训练的远程监督方法,该方法包含推理过程扩展策略(辅助训练大语言模型更有效地理解推理模式)及交叉验证策略(确保自动生成训练数据的质量)。为了评估 TableLLM 的性能,我们构建了针对文档与电子表格格式的定制化基准测试,并设计了可同时处理两种场景的结构化评估流程。系统性的评估结果表明,相较于现有各类通用型及表格数据专用型大语言模型,TableLLM 展现出显著优势。主页:https://tablellm.github.io/
主要作者简介

胡雨轩,中国人民大学信息学院2022级博士生,大数据科学与技术。研究兴趣包括大语言模型架构优化,模型压缩,推理加速等。

陈晓栋,中国人民大学信息学院2024级硕士生,计算机应用技术专业。研究兴趣包括大语言模型、模型压缩、推理加速等。

马泽尧,中国人民大学信息学院2023级硕士生,计算机应用技术专业。研究兴趣包括大语言模型、代码生成、模型评估等。

张博涵,中国人民大学信息学院2024级硕士生。研究兴趣包括大语言模型、推理扩展、模型评估等。

刘涵冰,中国人民大学信息学院2024届本科生,金融学-数据科学与大数据技术(工学)双学位实验班专业。研究兴趣包括机器学习、博弈论、机制设计等。

张晓康,中国人民大学信息学院2022级硕士生,研究方向为自然语言处理和大语言模型,参与发表论文近20篇,论文获引用1900余次。

罗思佳,中国人民大学信息学院2021级本科生,数据科学与大数据技术专业。研究兴趣包括自然语言处理、大语言模型、模型压缩等。

通讯作者:张静,中国人民大学信息学院计算机系教授。主要研究大模型后训练、压缩和推理加速以及在具身智能的应用。近年来任SIGKDD、IJCAI等领域内国际顶级学术会议高级程序委员会委员以及TKDE、中国科学等知名杂志审稿人。任AI Open杂志Associate Editor。
Copyright © 2015 School of Information, Renmin University of China. All rights reserved.
版权所有中国人民大学信息学院