学院新闻
College News

标题:GLM-Dialog: Noise-tolerant Pre-training for Knowledge-grounded Dialogue Generation
作者:张静(中国人民大学),张晓康(中国人民大学),张李牛牛(清华大学),于济凡(清华大学),姚子俊(清华大学),马泽尧(中国人民大学),徐轶琦(中国人民大学), 王昊华(清华大学), 张笑涵(智谱AI),林念宜(清华大学),卢孙瑞(清华大学),李娟子(清华大学),唐杰(清华大学)
录用会议: KDD 2023 (ADS)
论文概述:
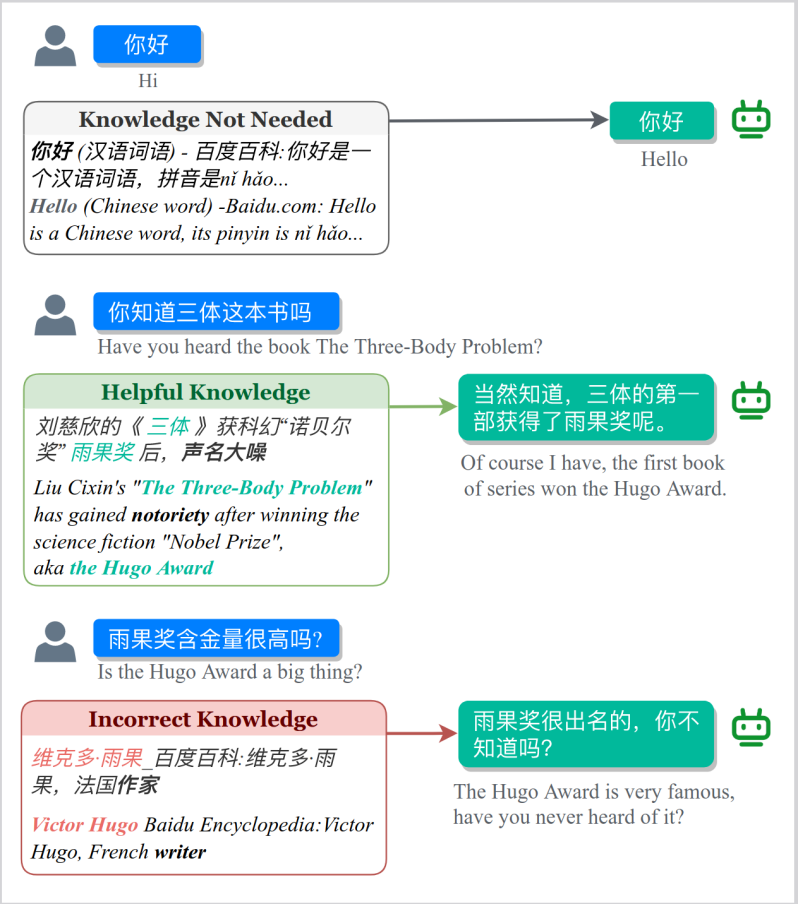
检索增强型大规模预训练语言模型(大模型)在减少事实错误方面取得了显著进展。然而,在确保检索内容的有用性方面仍存在挑战。尽管外部知识的整合至关重要,但考虑外部检索信息的不同类型也很重要的。外部检索到的信息通常可分为三类:正确且相关的知识、正确但不相关的知识和错误的知识。在这些类别中,重点关注利用第一类知识,即直接适用于用户查询或上下文的正确且相关的知识。目前来看,让大模型过滤和识别最相关的信息仍然是一个持续的挑战。
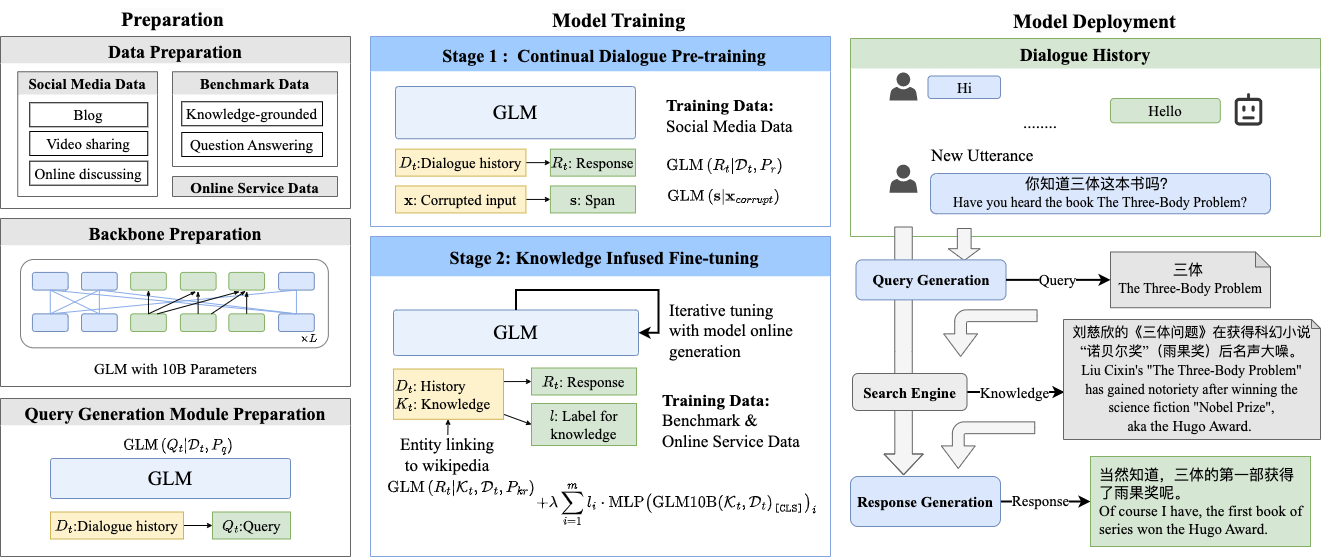
本文提出了GLM-Dialog:用于知识驱动对话生成的容忍噪声预训练方法。GLM-Dialog是知识驱动对话生成的创新方法,旨在解决噪声数据的挑战。所提出的方法包括两个阶段:无知识预训练和随后的外部知识和噪声识别训练。
第一阶段,从基准来源、社交媒体平台和在线服务收集了大量对话数据。这些数据用于训练GLM 10B模型,重点是让模型熟悉对话的结构和模式。这一初始预训练阶段使模型掌握生成连贯和上下文适当的回应的基本原理。
接下来进入第二阶段,模型被注入外部知识以增强对话生成能力。然而,引入外部知识会带来将不可靠或不正确的信息纳入生成回应的风险。为了减轻这种风险,训练过程中引入了噪声识别任务。该任务帮助模型学习在对话生成过程中识别并忽略噪声或不可靠信息,从而确保回应的质量和准确性。
通过结合这两个阶段,GLM-Dialog旨在创建一个容忍噪声的知识驱动对话生成的预训练框架。这种方法使模型能够在利用外部知识的同时对不准确性或噪声保持稳健性。
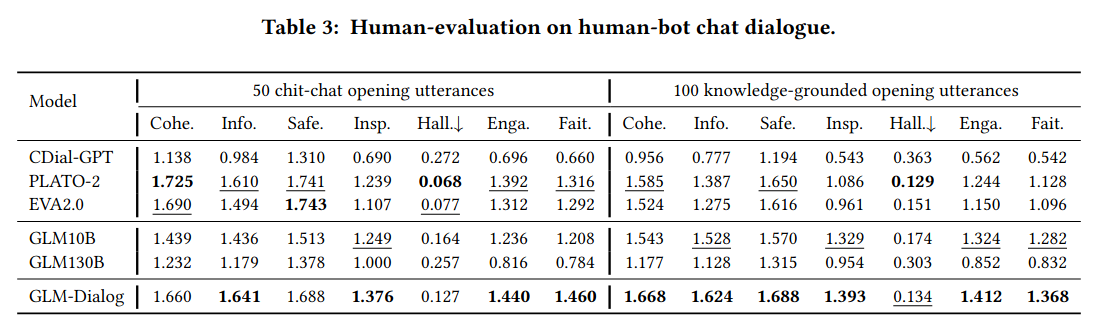
本文采用了自动评估、显式人工评估和隐式人工评估对GLM-Dialog的效果进行评测。这些方法使我们能够全面评估我们的对话模型的性能。所有的评估结果都表明,GLM-Dialog能够产生比其他对比模型更吸引人的回应。模型、代码以及部分训练数据请见https://github.com/RUCKBReasoning/GLM-Dialog。
作者简介:
张静,中国人民大学信息学院计算机系副教授。目前主要研究方向是知识图谱融合与推理等方面的相关研究。发表论文60余篇,其中包括十余篇KDD、SIGIR、WWW、ACL、TKDE、TOIS、IJCAI、AAAI、CIKM、WSDM等国际顶级会议或期刊论文。Google引用次数7000余次。近年来任WWW、IJCAI、PKDD/ECML等领域内国际顶级学术会议高级程序委员会委员以及TKDE、中国科学等知名杂志审稿人。任IEEE TBD以及AI Open期刊Associate Editor。

张晓康,中国人民大学2022级硕士生,大数据科学与工程专业。研究兴趣包括知识图谱、知识问答、对话系统等。

Copyright © 2015 School of Information, Renmin University of China. All rights reserved.
版权所有中国人民大学信息学院