学院新闻
College News

近日,信息学院金琴教授团队AIM3多媒体计算验室3篇长文《Token Mixing: Parameter-Efficient Transfer Learning from Image-Language to Video-Language》、《Accommodating Audio Modality in CLIP for Multimodal Processing》、《MPMQA: Multimodal Question Answering on Product Manuals》被人工智能领域顶级会议AAAI录用。AAAI(AAAI Conferenceon Artificial Intelligence,人工智能会议)是由人工智能促进协会举办的国际人工智能领域顶级会议之一,汇集了全球最顶尖的人工智能领域专家学者,一直是人工智能界的研究风向标,在学术界久负盛名。AAAI是中国计算机学会(CCF)推荐的A类国际学术会议,本届会议的论文录用率为19.6%。
3篇论文的第一作者分别是来自AIM3多媒体计算实验室的2021级硕士生刘玉琪、2020级硕士生阮璐丹和2020级博士生张良。
论文题目:Token Mixing: Parameter-Efficient Transfer Learning from Image-Language to Video-Language
作者:刘玉琪,徐鲁辉(腾讯),熊鹏飞(腾讯),金琴
通讯作者:金琴
论文概述:
将大规模预训练图像语言模型应用于视频语言任务面临两个挑战。一个是如何有效地将知识从静态图像转移到动态视频,另一个是如何应对由于模型规模不断增长而导致Fully Fine-tune的高昂成本。现有的尝试实现parameter-efficient的图像语言到视频语言迁移学习的工作可以分为两种类型:1)在2D Vision Transformer(ViT)之后附加一系列时间转换器块,2)将时间模块插入到ViT架构。虽然这两类方法只需要对新添加的组件进行微调,但仍有许多参数需要更新,并且它们仅在单个视频语言任务上得到验证。在这项工作中,基于我们对现有方法中不同时间建模组件的核心思想的分析,我们提出了一种Token Mix策略以允许跨帧交互,从而能够从预训练的图像语言模型转移到视频语言模型。通过从输入视频样本中选择和混合键集和值集来完成Token Mix。由于Token Mix不需要添加任何组件或模块,我们可以部分微调预训练的图像语言模型以实现parameter-efficient。我们进行了大量实验,将我们提出的Token Mix方法与其他parameter-efficient的迁移学习方法进行比较。我们的Token Mix方法在video understanding task和video generation task上都优于其他方法。此外,我们的方法在多个视频语言任务上取得了新的记录。

论文题目:Accommodating Audio Modality in CLIP for Multimodal Processing
作者:阮璐丹,胡安文,宋宇晴,张良,郑思鹏,金琴
通讯作者:金琴
论文概述:
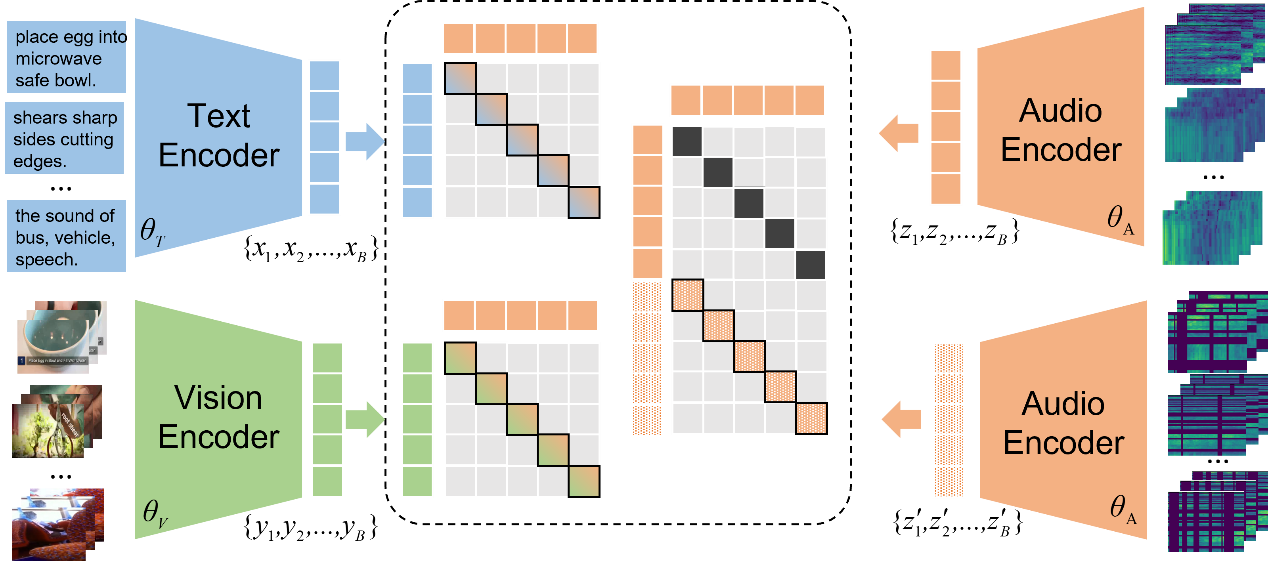
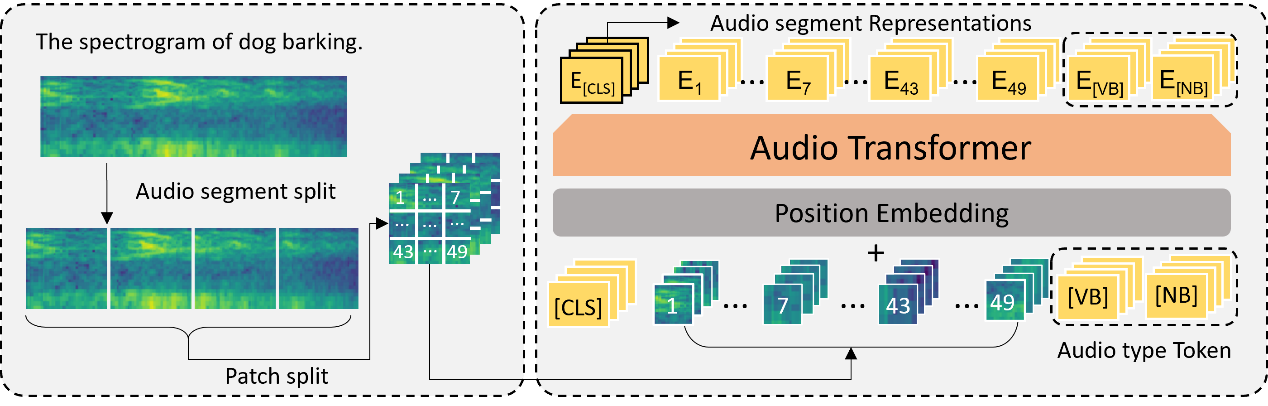
本文工作旨在利用已有的视觉-文本预训练模型(CLIP),将其扩展到音频模态,用来加强下游视频理解的相关任务(视频检索、视频文本描述)。传统的音频预训练工作由于处理音频时间过短、提取音频信息单一,无法直接引入进行跨模态建模。针对CLIP的模型特点和训练特点,本文采用CLIP的图像编码器作为音频编码器,首先转化音频为语谱图序列,输入编码器得到音频的序列特征。在音频编码器的训练上,我们同时采用模态间和模态内部的对比学习,对齐音频模态与其他模态,提升编码器音频信息抽取能力。此外,通用视频中的音频同时包含语义信息和非语义信息,我们在音频编码器最后引入[VB],[NB]两个token,用语义信息为主的视频数据集Howto100M、非语义信息为主的视频数据集Audioset分别训练。我们的方法在多个数据集的视频检索、视频描述生成中都获取了显著提升,超过了原来的SOTA。
论文题目:MPMQA: Multimodal Question Answering on Product Manuals
作者:张良,胡安文,张静(三星),胡硕(三星),金琴
通讯作者:金琴
论文概述:
视觉信息对于在产品说明书的理解起十分关键的作用。现有的产品说明书问题回答(PMQA)任务只考虑了说明书中的文本内容,忽略了诸如产品图片和图例等视觉信息。该工作中我们提出了多模态产品说明书问题回答任务(MPMQA)。对于每个问题,MPMQA要求模型处理多模态说明书内容,并给出多模态的回答。我们通过人工标注构建了PM209数据集以支持MPMQA任务,PM209数据集由209份产品说明书构成,涵盖27种常见电子产品品牌。PM209将说明书的每一页划分为6种语义区域,并根据内容标注了共计22021个问题-回答对。每个问题的回答由文本回答(自然语言句子)和视觉回答(相关视觉区域)构成。由于说明书通常由多个页面构成,而问题往往只与部分页有关,MPMQA任务可以分为两个子任务:检索问题相关页和生成多模态回答。我们基于多任务学习,提出了可以完成上述两个子任务的统一URA模型,实验表明统一的URA模型能够与多个单任务模型表现相当。

作者简介:
刘玉琪,中国人民大学信息学院2021级硕士,计算机应用技术专业,主要研究方向是多模态学习,视频文本检索等。

阮璐丹,中国人民大学信息学院2020级硕士,计算机应用技术专业,主要研究方向是多模态预训练,多模态生成等。

张良,中国人民大学信息学院2020级博士,大数据科学与工程专业,主要研究方向是多模态和多语言理解。

金琴,中国中国人民大学信息学院计算机系教授,多媒体计算实验室(AIM3)负责人。主要研究领域为多媒体智能计算、人机交互。

Copyright © 2015 School of Information, Renmin University of China. All rights reserved.
版权所有中国人民大学信息学院