学院新闻
College News

近日,信息学院范举副教授团队论文《Domain Adaptation for Deep Entity Resolution》被数据库领域顶级会议ACM SIGMOD(Special Interest Group on Management Of Data)2022录用为长文。
ACM SIGMOD数据管理国际会议(Special Interest Group on Management Of Data.)由美国计算机协会(ACM)数据管理专业委员会(SIGMOD)发起,是数据库领域具有最高学术地位的国际性会议,论文审稿非常严格苛刻。
标题:Domain Adaptation for Deep Entity Resolution
作者:涂荐泓(中国人民大学),范举(中国人民大学),汤南(卡塔尔计算研究所),王芃(中国人民大学),柴成亮(清华大学),李国良(清华大学),范瑞雪(中国人民大学),杜小勇(中国人民大学)
通信作者:范举,中国人民大学
录用会议:SIGMOD 2022
代码开源地址:https://github.com/ruc-datalab/DADER
研究动机:
实体解析是数据集成领域的重要研究问题,如图1(a)所示,是指从给定的两张关系表中找出所有代表相同实体的元组,此例中有两对实体相同。
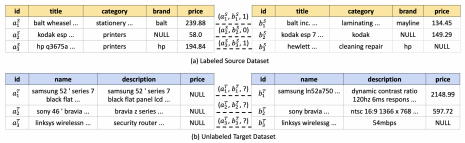
图1
现有的解决方案主要是依赖于深度学习模型的有监督训练,这需要大量的标注数据作为训练集。给每一个数据集都收集标注数据是需要很高成本的,因此我们提出了DADER模型。对于给定的任意数据集(称作目标数据集T),不需要标注出训练集,仅利用现有的一些公开的已标注的数据集(称作源数据集S)来训练模型(记为M),从而实现在目标数据集上的良好性能。但由于S和T两个数据集可能来自两个完全不同的域,数据分布存在较大差异,直接将M应用于T可能无法取得好的性能,此处引出域适应技术,域适应技术在CV和NLP领域已经被广泛研究过,但其在实体解析问题上的性能还未被讨论过,DADER设计了域适应算法来调整模型M,从而实现M在T上的良好性能。
图2 形象的展示了源数据集S(圆点)和目标数据集T(方块),在(a)中由于两个数据集的分布不同,在S上学到的模型M(绿色虚线)无法准确预测T。于是在(b)中,DADER通过调整两个数据集的分布,学习不仅适用于S,还适用于T的模型。
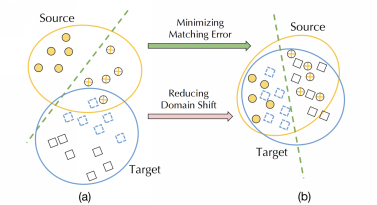
图2
解决方案:
首先,我们设计了将域适应技术应用于实体解析问题的通用模型框架,该框架包含三个主要部分:Feature Extractor,Matcher,和Feature Aligner。如图3所示,Feature Extractor将实体对提取出特征,Matcher是判断该实体对是否相同的分类器,Feature Aligner是实现域适应的核心模块,其作用是融合两个数据集的特征分布,从而实现Matcher在两个数据集上的高质量预测。
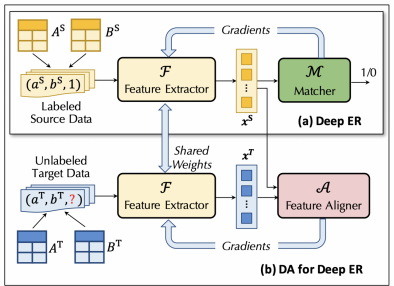
图3
其次,我们定义了以上模型的解决方案设计空间。如表1所示,对于Feature Extractor, 我们主要应用两类高效的深度学习网络:循环神经网络RNN和预训练语言模型LMs。 对于Matcher,我们使用最常用且高效的MLP。对于Feature Aligner,我们设计了三大类主流的域适应技术:Discrepancy-based,Adversarial-based,和Reconstruction-based。Discrepancy-base通过减小两个分布的距离度量指标来减小数据差异,Adversarial-based通过对抗训练的思想使两个数据集的特征融合,Reconstruction-based通过同一个Encoder和Decoder网络提取出两个数据集通用的特征。我们提出了(a)到(f)六种代表性方法来探讨不同域适应技术的性能,图4展示了该六种方法的具体模型结构(都是图3的通用框架的具体实现)。
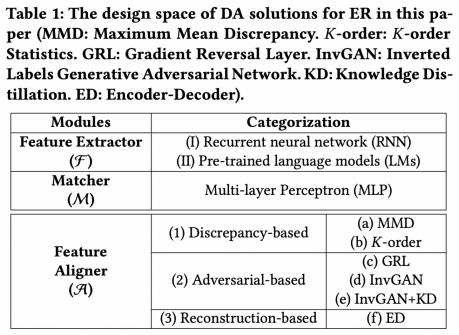
表1
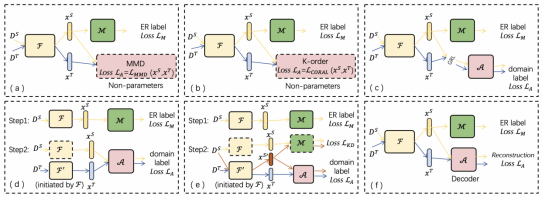
图4
主要实验结果:
(1)域适应技术可以有效提升模型在目标数据集上的性能。
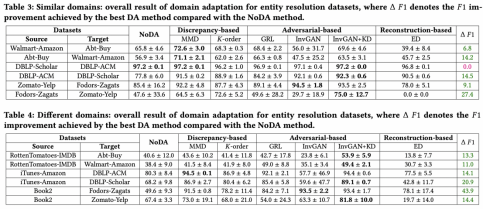
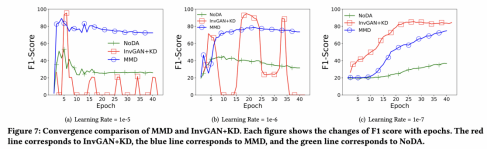
(2)Adversarial-based可以实现最高的提升,但训练过程不太稳定;而Discrepancy-based相对比较稳定。
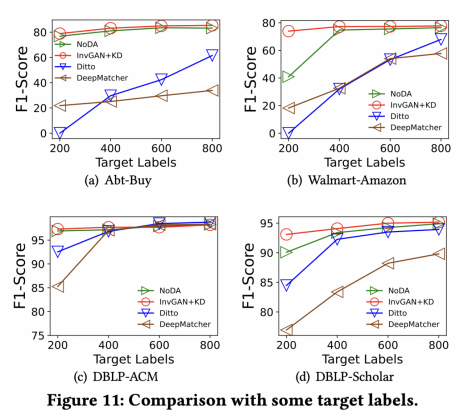
(3)在有少量标注的情况下,使用域适应技术的模型可以实现比SOTA方法更高的性能。
总结:
本文实现了域适应技术在实体解析问题上的SOTA,设计了通用灵活的模型架构,定义了有效的解决方案设计空间,并探讨了六种代表性方法的性能,通过大量实验探讨了域适应技术在实体解析问题上的可用性与限制,为该问题的后续研究提供了有力的指导。
作者简介:
涂荐泓,中国人民大学信息学院2020级学术硕士,计算机应用技术专业,主要研究方向是数据库与数据挖掘,目前已发表2篇CCF-A类论文(VLDB和SIGMOD)。

范举,中国人民大学数据工程与知识工程教育部重点实验室副教授、博士生导师、中国计算机学会数据库专家委员会委员、大数据专家委员会委员。近年来聚焦人在回路的数据融合、众包数据管理、大数据分析等研究方向,相关成果在计算机领域A类期刊和会议上发表论文40余篇。作为负责人主持了国家自然科学基金优青项目、面上项目、重点项目课题,以及多项腾讯犀牛鸟基金项目。获得2017年度ACM China Rising Award。

Copyright © 2015 School of Information, Renmin University of China. All rights reserved.
版权所有中国人民大学信息学院